第24章 UnicodeとJavaScript
本章はUnicodeの概要と、JavaScriptでの扱い方について簡単に説明します。
Unicodeの歴史
最初のUnicodeドラフト提案は1988年に発表されました。その後も作業は続けられ、ワーキンググループは拡大しました。Unicodeコンソーシアムは1991年1月3日に設立されました。
Unicodeコンソーシアムは、ソフトウェアの国際化標準とデータ、特にUnicode標準の開発、維持、促進に特化した非営利団体です[...]
Unicode 1.0標準の第1巻は1991年10月、第2巻は1992年6月に発行されました。
重要なUnicodeの概念
文字の概念は単純に見えるかもしれませんが、多くの側面があります。それがUnicodeが非常に複雑な標準である理由です。以下は、重要な基本概念です。
- 文字とグラフェム
- これらの2つの用語は非常に類似した意味を持ちます。文字はデジタルエンティティであり、グラフェムは書記言語の原子単位(アルファベットの文字、タイポグラフィックリガチャ、漢字、句読点など)です。プログラマーは文字で考えますが、ユーザーはグラフェムで考えます。単一のグラフェムを表すために、複数の文字が使用される場合があります。たとえば、文字oと文字^(サーカムフレックスアクセント)を組み合わせることで、単一のグラフェムôを作成できます。
- グリフ
- これはグラフェムを表示する具体的な方法です。場合によっては、同じグラフェムが、そのコンテキストやその他の要因に応じて異なる表示になります。たとえば、グラフェムfとiは、リガチャグリフで接続されたグリフfとグリフiとして、またはリガチャなしで表示できます。
- コードポイント
- Unicodeはサポートする文字をコードポイントと呼ばれる数値で表します。コードポイントの16進数の範囲は0x0〜0x10FFFF(16ビットの17倍)です。
- コードユニット
- コードポイントを保存または送信するには、固定長のデータ片であるコードユニットとしてエンコードします。長さはビットで測定され、エンコーディングスキームによって決定されます。UnicodeにはUTF-8やUTF-16など、いくつかのエンコーディングスキームがあります。名前の数字は、コードユニットの長さをビットで示しています。コードポイントが単一のコードユニットに収まらない場合は、複数のユニットに分割する必要があります。つまり、単一のコードポイントを表すために必要なコードユニットの数は可変です。
- BOM(バイトオーダーマーク)
コードユニットが1バイトより大きい場合、バイトオーダーが重要になります。BOMは、テキストの先頭に配置される単一の擬似文字(複数のコードユニットとしてエンコードされる場合もあります)であり、コードユニットがビッグエンディアン(最上位バイトが先頭)かリトルエンディアン(最下位バイトが先頭)かを表します。BOMのないテキストのデフォルトはビッグエンディアンです。BOMは使用されているエンコーディングも示します。UTF-8、UTF-16などでは異なります。さらに、Webブラウザがテキストのエンコーディングに関する他の情報を持っていない場合、Unicodeのマーカーとして機能します。ただし、いくつかの理由から、BOMはあまり使用されません。
- UTF-8は、圧倒的に人気のあるUnicodeエンコーディングであり、バイトの並べ方は1つしかないため、BOMは必要ありません。
- いくつかの文字エンコーディングは固定バイトオーダーを指定します。その場合、BOMを使用しないでください。例としては、UTF-16BE(UTF-16ビッグエンディアン)、UTF-16LE、UTF-32BE、UTF-32LEなどがあります。これは、メタデータとデータが分離され、混同されることがないため、バイトオーダーを処理するより安全な方法です。
- 正規化
- 同じグラフェムを複数の方法で表現できる場合があります。たとえば、グラフェムöは、単一のコードポイントとして、またはoに続く結合文字¨(ウムラウト、二重ドット)として表現できます。正規化とは、テキストを標準的な表現に変換することです。同等のコードポイントとコードポイントのシーケンスはすべて、同じコードポイント(またはコードポイントのシーケンス)に変換されます。これは、テキスト処理(テキストの検索など)に役立ちます。Unicodeはいくつかの正規化を指定しています。
- 文字プロパティ
各Unicode文字には、仕様によっていくつかのプロパティが割り当てられており、その一部を以下に示します。
名前。大文字A〜Z、数字0〜9、ハイフン(-)、および<space>で構成される英語の名前。2つの例
- 「λ」の名前は「GREEK SMALL LETTER LAMBDA」です。
- 「!」の名前は「EXCLAMATION MARK」です。
- 一般カテゴリ。文字を文字、大文字、数字、句読点などのカテゴリに分割します。
- 時代。どのバージョンのUnicodeで文字が導入されましたか(1.0、1.1、2.0など)?
- 非推奨。文字の使用は推奨されなくなっていますか?
- その他多数.
コードポイント
コードポイントの範囲は当初16ビットでした。Unicodeバージョン2.0(1996年7月)で拡張され、現在は0〜16と番号が付けられた17のプレーンに分割されています。各プレーンは16ビット(16進表記:0x0000〜0xFFFF)を構成します。したがって、以下の16進数の範囲では、下の4桁を超える桁はプレーンの番号を表します。
- プレーン0、基本多言語面(BMP):0x0000〜0xFFFF
- プレーン1、補足多言語面(SMP):0x10000〜0x1FFFF
- プレーン2、補足漢字面(SIP):0x20000〜0x2FFFF
- プレーン3〜13、未割り当て
- プレーン14、補足特殊用途面(SSP):0xE0000〜0xEFFFF
- プレーン15〜16、補足プライベート使用領域(SPUA A/B):0x0F0000〜0x10FFFF
プレーン1〜16は補足面またはアストラル面と呼ばれます。
Unicodeエンコーディング
UTF-32(Unicode Transformation Format 32)は32ビットコードユニットを使用するフォーマットです。任意のコードポイントを単一のコードユニットでエンコードできるため、これは唯一の固定長エンコーディングになります。その他のエンコーディングでは、ポイントをエンコードするために必要なユニットの数は可変です。
UTF-16は16ビットコードユニットを使用するフォーマットであり、コードポイントを表すために1〜2ユニットが必要です。BMPコードポイントは単一のコードユニットで表すことができます。上位のコードポイントは20ビット(16ビット×16ビット)であり、0x10000(BMPの範囲)を引いた後です。これらのビットは2つのコードユニット(いわゆるサロゲートペア)としてエンコードされます。
次の表(Unicode標準6.2.0、表3-5から改変)は、ビットの分布を視覚的に示しています。
| コードポイント | UTF-16コードユニット |
xxxxxxxxxxxxxxxx(16ビット) | xxxxxxxxxxxxxxxx |
pppppxxxxxxyyyyyyyyyy(21ビット=5+6+10ビット) | 110110qqqqxxxxxx 110111yyyyyyyyyy(qqqq = ppppp − 1) |
このエンコーディングスキームを有効にするために、BMPには、使用されていないコードポイントの穴があり、その範囲は0xD800〜0xDFFFです。したがって、上位サロゲート、下位サロゲート、BMPコードポイントの範囲は互いに素であり、エラーが発生した場合でもデコードが堅牢になります。次の関数は、コードポイントをUTF-16としてエンコードします(後で使用方法の例を示します)。
functiontoUTF16(codePoint){varTEN_BITS=parseInt('1111111111',2);functionu(codeUnit){return'\\u'+codeUnit.toString(16).toUpperCase();}if(codePoint<=0xFFFF){returnu(codePoint);}codePoint-=0x10000;// Shift right to get to most significant 10 bitsvarleadingSurrogate=0xD800|(codePoint>>10);// Mask to get least significant 10 bitsvartrailingSurrogate=0xDC00|(codePoint&TEN_BITS);returnu(leadingSurrogate)+u(trailingSurrogate);}
- 0000〜007F:0xxxxxxx(7ビット、1バイトに格納)
- 0080〜07FF:110xxxxx、10xxxxxx(5+6ビット=11ビット、2バイトに格納)
- 0800〜FFFF:1110xxxx、10xxxxxx、10xxxxxx(4+6+6ビット=16ビット、3バイトに格納)
- 10000〜1FFFFF:11110xxx、10xxxxxx、10xxxxxx、10xxxxxx(3+6+6+6ビット=21ビット、4バイトに格納)。最高のコードポイントは10FFFFであるため、UTF-8には余分なスペースがあります。
最上位ビットが0でない場合、0の前にある1の数はそのシーケンスに含まれるコードユニットの数を示します。最初のコードユニット以降のすべてのコードユニットには、ビットプレフィックス10があります。したがって、最初のコードユニットと後続のコードユニットの範囲は互いに素であり、エンコーディングエラーからの回復に役立ちます。
UTF-8は、最も普及しているUnicodeフォーマットになりました。当初、その人気はASCIIとの下位互換性によるものでした。その後、オペレーティングシステム、プログラミング環境、アプリケーション全体での広範で一貫したサポートにより、人気が高まりました。
JavaScriptソースコードとUnicode
JavaScriptは、Unicodeソースコードを内部(解析中)と外部(ファイルの読み込み中)の2つの方法で処理します。
内部のソースコード
内部的には、JavaScriptソースコードはUTF-16コードユニットのシーケンスとして扱われます。ECMAScript仕様のセクション6によると
ECMAScriptソーステキストは、Unicode文字エンコーディングバージョン3.0以降の一連の文字として表されます。 [...] この仕様の目的上、ECMAScriptソーステキストは16ビットコードユニットのシーケンスであると想定されます。 [...] 実際のソーステキストが16ビットコードユニット以外の形式でエンコードされている場合、最初にUTF-16に変換されたかのように処理する必要があります。
識別子、文字列リテラル、および正規表現リテラルでは、任意のコードユニットをUnicodeエスケープシーケンス\uHHHHで表現することもできます。HHHHは4つの16進数桁です。例:
> var f\u006F\u006F = 'abc'; > foo 'abc' > var λ = 123; > \u03BB 123
つまり、ソースコードでASCII範囲を超えることなく、リテラルと変数名にUnicode文字を使用できます。
文字列リテラルでは、別の種類のエスケープも使用できます。16進エスケープシーケンスは、0x00~0xFFの範囲のコードユニットを表す2桁の16進数を使用します。例:
> '\xF6' === 'ö' true > '\xF6' === '\u00F6' true
ソースコード(外部)
内部的にはUTF-16が使用されますが、JavaScriptソースコードは通常その形式で保存されません。<script>タグを介してウェブブラウザがソースファイルを読み込むと、エンコーディングが次のように決定されます
- ファイルがBOMで始まる場合、使用されるBOMに応じてエンコーディングはUTFのバリアントになります。
そうでない場合、ファイルがHTTP(S)を介して読み込まれると、
Content-Typeヘッダーでcharsetパラメーターを使用してエンコーディングを指定できます。例:Content-Type: application/javascript; charset=utf-8
ヒント
JavaScriptファイルの正しいメディアタイプ(以前はMIMEタイプとして知られていました)は
application/javascriptです。ただし、古いブラウザ(例:Internet Explorer 8以前)はtext/javascriptの方が最も確実に動作します。<script>タグのtype属性のデフォルト値は残念ながらtext/javascriptです。少なくともJavaScriptの場合はその属性を省略できます。含めるメリットはありません。- そうでない場合、
<script>タグがcharset属性を持つ場合、そのエンコーディングが使用されます。type属性が有効なメディアタイプを保持していても、そのタイプはcharsetパラメーターを持つことはできません(前述のContent-Typeヘッダーの場合と同様です)。これにより、charsetとtypeの値が衝突しないことが保証されます。 そうでない場合、
<script>タグが存在するドキュメントのエンコーディングが使用されます。例えば、これは<meta>タグがドキュメントがUTF-8でエンコードされていることを宣言するHTML5ドキュメントの先頭です。<!doctype html><html><head><metacharset="UTF-8">...常にエンコーディングを指定することを強くお勧めします。指定しないと、ロケール固有のデフォルトエンコーディングが使用されます。つまり、国によってファイルの表示が異なります。最下位7ビットだけがロケール間で比較的安定しています。
私の推奨事項を要約すると次のとおりです。
- 独自のアプリケーションでは、Unicodeを使用できます。ただし、アプリのHTMLページのエンコーディングをUTF-8として指定する必要があります。
- ライブラリの場合、ASCII(7ビット)のコードをリリースするのが最も安全です。
一部のミニファイアーツールは、7ビットを超えるUnicodeコードポイントを含むソースを「7ビットクリーン」なソースに変換できます。それらは、ASCII以外の文字をUnicodeエスケープに置き換えることでこれを行います。例えば、UglifyJSの次の呼び出しはファイルtest.jsを変換します:
uglifyjs -b beautify=false,ascii-only=true test.js
ファイルtest.jsは次のようになります。
varσ='Köln';
UglifyJSの出力は次のようになります。
var\u03c3="K\xf6ln";
次のネガティブな例を考えてみましょう。しばらくの間、ライブラリD3.jsはUTF-8で公開されていました。エンコーディングがUTF-8でないページから読み込まれた場合、コードに次のようなステートメントが含まれていたため、エラーが発生しました。
varπ=Math.PI,ε=1e-6;
識別子πとεは正しくデコードされず、有効な変数名として認識されませんでした。さらに、7ビットを超えるコードポイントを持つ文字列リテラルの一部も正しくデコードされませんでした。回避策として、charset属性を<script>タグに追加することでコードを読み込むことができます。
<scriptcharset="utf-8"src="d3.js"></script>
JavaScript文字列とUnicode
JavaScript文字列はUTF-16コードユニットのシーケンスです。ECMAScript仕様によると、セクション8.4
文字列が実際のテキストデータを含む場合、各要素は単一のUTF-16コードユニットと見なされます。
エスケープシーケンス
前述のように、文字列リテラルでUnicodeエスケープシーケンスと16進エスケープシーケンスを使用できます。たとえば、oとウムラウト(コードポイント0x0308)を組み合わせることで、文字öを作成できます:
> console.log('o\u0308')
öこれは、ウェブブラウザコンソールやNode.js REPLなどのJavaScriptコマンドラインで動作します。この種の文字列をウェブページのDOMに挿入することもできます。
エスケープによるアストラルプレーン文字への参照
ウェブ上には多くの優れたUnicodeシンボルテーブルがあります。Tim Whitlockの“Emoji Unicode Tables”を見て、最新のUnicodeフォントにあるシンボルの数に驚嘆してください。テーブル内のシンボルのどれも画像ではなく、すべてフォントグリフです。JavaScriptを介してアストラルプレーンにあるUnicode文字を表示したいと仮定します(明らかに、そうする際にはリスクがあります。すべてのフォントがそのようなすべての文字をサポートしているとは限りません)。たとえば、コードポイント0x1F404の牛を考えてみましょう。 .
.
文字をコピーして、UnicodeでエンコードされたJavaScriptソースに直接貼り付けることができます。
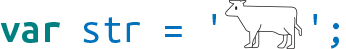
JavaScriptエンジンはソース(ほとんどの場合UTF-8)をデコードし、2つのUTF-16コードユニットを持つ文字列を作成します。あるいは、2つのコードユニットを自分で計算してUnicodeエスケープシーケンスを使用することもできます。この計算を実行するウェブアプリもあります。たとえば:
前に定義した関数toUTF16もこれを実行します。
> toUTF16(0x1F404) '\\uD83D\\uDC04'
UTF-16サロゲートペア(0xD83D、0xDC04)は確かに牛をエンコードします。
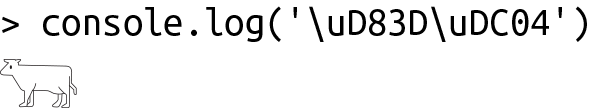
文字数のカウント
文字列にサロゲートペア(単一のコードポイントをエンコードする2つのコードユニット)が含まれている場合、lengthプロパティはグラフェムをカウントしなくなります。コードユニットをカウントします:

これは、Node.jsにバンドルされているMathias BynensのPunycode.jsなどのライブラリを使用して修正できます。
> var puny = require('punycode');
> puny.ucs2.decode(str).length
1Unicode正規化
文字列を検索したり比較したりする場合、正規化する必要があります。たとえば、ライブラリunorm(Bjarke Walling作成)を使用します。
JavaScript正規表現とUnicode
JavaScriptの正規表現におけるUnicodeのサポート(第19章を参照)は非常に限られています。たとえば、「大文字」などのUnicodeカテゴリに一致させる方法はありません。
改行文字は一致に影響を与えます。改行文字は次の表に指定されている4つの文字のいずれかです。
| コードユニット | 名前 | 文字エスケープシーケンス |
\u000A | 改行 |
|
\u000D | 復帰 |
|
\u2028 | ラインセパレータ | |
\u2029 | パラグラフセパレータ |
次の正規表現構造はUnicodeに基づいています。
\s \S(空白、非空白)にはUnicodeベースの定義があります。> /^\s$/.test('\uFEFF') true-
.(ドット)は、改行文字を除くすべてのコードユニット(コードポイントではありません!)に一致します。任意のコードポイントに一致させる方法については、次のセクションを参照してください。 - 複数行モード
/m:複数行モードでは、アサーション^は入力の先頭と改行文字の後に一致します。アサーション$は改行文字の前に、入力の最後に一致します。複数行モード以外では、それぞれ入力の先頭または末尾のみに一致します。
その他の重要な文字クラスには、UnicodeではなくASCIIに基づいた定義があります。
-
\d \D(数字、非数字):数字は[0-9]と同等です。 -
\w \W(単語文字、非単語文字):単語文字は[A-Za-z0-9_]と同等です。 \b \B(単語区切り文字、単語内):単語は単語文字([A-Za-z0-9_])のシーケンスです。たとえば、文字列'über'では、文字クラスエスケープ\bは文字bを単語の開始として認識します。> /\bb/.test('über') true
任意のコードユニットと任意のコードポイントの一致
任意のコードユニットに一致させるには、[\s\S]を使用できます。Atoms: Generalを参照してください。
任意のコードポイントに一致させるには、次を使用する必要があります。[20]
([\0-\uD7FF\uE000-\uFFFF]|[\uD800-\uDBFF][\uDC00-\uDFFF])
上記の正規表現は次のように機能します。
([BMP code point]|[leading surrogate][trailing surrogate])
これらの範囲はすべて互いに素であるため、この正規表現は適切に形成されたUTF-16文字列のコードポイントに正しく一致します。
ライブラリ
いくつかのライブラリは、JavaScriptでのUnicodeの処理に役立ちます:
- Regenerateは、任意のコードユニットに一致させるための前述のような範囲の生成に役立ちます。ビルドツールのコンポーネントとして使用することを意図していますが、動的に使用してさまざまなことを試すこともできます。
XRegExpは、次の3つの構造のいずれかを使用して、Unicodeカテゴリ、スクリプト、ブロック、およびプロパティに一致させるための公式アドオンを持つ正規表現ライブラリです。
\p{...} \p{^...} \P{...}たとえば、
\p{Letter}はさまざまなアルファベットの文字に一致しますが、\p{^Letter}と\P{Letter}はどちらもその他のすべてのコードポイントに一致します。第30章には、XRegExpの概要が簡潔に記載されています。- ECMAScript国際化API(ECMAScript国際化APIを参照)は、Unicode対応の照合(文字列のソートと検索)などを提供します。
参考文献および章の出典
Unicodeの詳細については、以下を参照してください。
- Wikipediaには、Unicodeとその用語に関する優れた項目がいくつかあります。
- Unicodeコンソーシアムの公式ウェブサイトであるUnicode.orgとそのFAQも優れたリソースです。
- Joel Spolsky氏の導入記事“The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)”(ソフトウェア開発者が絶対に知っておくべきUnicodeと文字セットに関する絶対最小限のこと(言い訳なし!))は役に立ちます。
JavaScriptにおけるUnicodeサポートの詳細については、以下を参照してください。
謝辞
この章の作成に貢献してくださった方々:Mathias Bynens (@mathias)、Anne van Kesteren (@annevk)、およびCalvin Metcalf (@CWMma)。