19 Unicode – 簡単な紹介(上級)
- 19.1 コードポイントとコードユニット
- 19.1.1 コードポイント
- 19.1.2 Unicodeコードポイントのエンコーディング:UTF-32、UTF-16、UTF-8
- 19.2 Web開発で使用されるエンコーディング:UTF-16とUTF-8
- 19.2.1 ソースコード(内部表現):UTF-16
- 19.2.2 文字列:UTF-16
- 19.2.3 ファイル内のソースコード:UTF-8
- 19.3 グラフェムクラスタ – 真の文字
- 19.3.1 グラフェムクラスタとグリフ
Unicodeは、世界の大部分の文字体系でテキストを表し、管理するための標準です。テキストを扱うほとんどの最新のソフトウェアはUnicodeをサポートしています。この標準はUnicodeコンソーシアムによって維持されています。新しいバージョンの標準は毎年(新しい絵文字などと共に)公開されます。Unicodeバージョン1.0.0は1991年10月に公開されました。
19.1 コードポイントとコードユニット
Unicodeを理解するために重要な2つの概念があります。
- コードポイントは、Unicodeテキストの原子単位を表す数値です。そのほとんどは可視記号を表しますが、記号の側面(文字のアクセント、絵文字の肌の色など)を指定するなど、他の意味を持つこともあります。
- コードユニットは、Unicodeテキストを保存または送信するためにコードポイントをエンコードする数値です。1つ以上のコードユニットが1つのコードポイントをエンコードします。各コードユニットは同じサイズを持ち、使用されるエンコーディング形式によって異なります。最も一般的な形式であるUTF-8は、8ビットのコードユニットを使用します。
19.1.1 コードポイント
最初のUnicodeバージョンでは、16ビットのコードポイントを使用していました。それ以来、文字数は大幅に増加し、コードポイントのサイズは21ビットに拡張されました。これらの21ビットは、それぞれ16ビットの17面で区切られています。
- 面0:基本多言語面(BMP)、0x0000–0xFFFF
- ほとんどの現代言語(ラテン文字、アジア文字など)と多くの記号の文字が含まれています。
- 面1:補足多言語面(SMP)、0x10000–0x1FFFF
- 歴史的な文字体系(例:エジプトのヒエログリフや楔形文字)と追加の現代文字体系をサポートします。
- 絵文字やその他の多くの記号をサポートします。
- 面2:補足漢字面(SIP)、0x20000–0x2FFFF
- 追加のCJK(中国語、日本語、韓国語)漢字が含まれています。
- 面3–13:未割り当て
- 面14:補足特殊用途面(SSP)、0xE0000–0xEFFFF
- タグ文字やグリフバリエーションセレクタなどの非グラフィック文字が含まれています。
- 面15–16:補足プライベート使用領域(SPUA A/B)、0x0F0000–0x10FFFF
- ISOとUnicodeコンソーシアム以外の団体による文字割り当てに使用できます。標準化されていません。
面1~16は、補足面またはアストラル面と呼ばれます。
いくつかの文字のコードポイントを確認してみましょう。
> 'A'.codePointAt(0).toString(16)
'41'
> 'ü'.codePointAt(0).toString(16)
'fc'
> 'π'.codePointAt(0).toString(16)
'3c0'
> '🙂'.codePointAt(0).toString(16)
'1f642'コードポイントの16進数は、最初の3つの文字は面0(16ビット以内)にあり、絵文字は面1にあることを示しています。
19.1.2 Unicodeコードポイントのエンコーディング:UTF-32、UTF-16、UTF-8
コードポイントをエンコードする主な方法は、3つのUnicode変換形式(UTF):UTF-32、UTF-16、UTF-8です。各形式の末尾の数字は、そのコードユニットのサイズ(ビット単位)を示します。
19.1.2.1 UTF-32(Unicode変換形式32)
UTF-32は、コードユニットの格納に32ビットを使用し、コードポイントごとに1つのコードユニットになります。この形式は、固定長エンコーディングを持つ唯一の形式です。他の形式はすべて、単一のコードポイントをエンコードするために可変数のコードユニットを使用します。
19.1.2.2 UTF-16(Unicode変換形式16)
UTF-16は16ビットのコードユニットを使用します。コードポイントは次のようにエンコードされます。
BMP(Unicodeの先頭16ビット)は単一のコードユニットに格納されます。
アストラル面:BMPは0x10_000個のコードポイントで構成されています。Unicodeの合計コードポイント数は0x110_000個であるため、残りの0x100_000個のコードポイント(20ビット)をまだエンコードする必要があります。BMPには、必要なストレージを提供する割り当てられていないコードポイントの2つの範囲があります。
- 最上位10ビット(上位サロゲート):0xD800-0xDBFF
- 最下位10ビット(下位サロゲート):0xDC00-0xDFFF
言い換えれば、末尾の2つの16進数は8ビットに寄与します。しかし、BMPが次の2桁のペアのいずれかで始まる場合にのみ、これらの8ビットを使用できます。
- D8、D9、DA、DB
- DC、DD、DE、DF
サロゲートごとに、4つのペアを選択できます。これが残りの2ビットの出所です。
その結果、各UTF-16コードユニットは、常に上位サロゲート、下位サロゲート、またはBMPコードポイントのいずれかをエンコードします。
UTF-16でエンコードされたコードポイントの2つの例を次に示します。
- コードポイント0x03C0(π)はBMPにあり、したがって単一のUTF-16コードユニット0x03C0で表すことができます。
- コードポイント0x1F642(
🙂)はアストラル面にあり、2つのコードユニット0xD83Dと0xDE42で表されます。
19.1.2.3 UTF-8(Unicode変換形式8)
UTF-8は8ビットのコードユニットを使用します。コードポイントをエンコードするために1〜4個のコードユニットを使用します。
| コードポイント | コードユニット |
|---|---|
| 0000–007F | 0bbbbbbb(7ビット) |
| 0080–07FF | 110bbbbb、10bbbbbb(5+6ビット) |
| 0800–FFFF | 1110bbbb、10bbbbbb、10bbbbbb(4+6+6ビット) |
| 10000–1FFFFF | 11110bbb、10bbbbbb、10bbbbbb、10bbbbbb(3+6+6+6ビット) |
注記
- 各コードユニットのビットプレフィックスは、次のことを教えてくれます。
- 一連のコードユニットの最初ですか?はいの場合は、いくつのコードユニットが続きますか?
- 一連のコードユニットの2番目以降ですか?
- 0000–007F範囲の文字マッピングはASCIIと同じであるため、古いソフトウェアとのある程度の後方互換性があります。
3つの例
| 文字 | コードポイント | コードユニット |
|---|---|---|
| A | 0x0041 | 01000001 |
| π | 0x03C0 | 11001111, 10000000 |
🙂 |
0x1F642 | 11110000, 10011111, 10011001, 10000010 |
19.2 Web開発で使用されるエンコーディング:UTF-16とUTF-8
Web開発で使用されるUnicodeエンコーディング形式は、UTF-16とUTF-8です。
19.2.1 ソースコード(内部表現):UTF-16
ECMAScript仕様では、ソースコードは内部的にUTF-16として表現されます。
19.2.2 文字列:UTF-16
JavaScript文字列の文字は、UTF-16コードユニットに基づいています。
> const smiley = '🙂';
> smiley.length
2
> smiley === '\uD83D\uDE42' // code units
trueUnicodeと文字列の詳細については、§20.7「テキストの原子:コードポイント、JavaScript文字、グラフェムクラスタ」を参照してください。
19.2.3 ファイル内のソースコード:UTF-8
HTMLとJavaScriptは、現在ほとんどの場合UTF-8でエンコードされています。
たとえば、HTMLファイルは現在通常このように始まります。
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
···Webブラウザで読み込まれるHTMLモジュールの場合、標準エンコーディングもUTF-8です。
19.3 グラフェムクラスタ – 真の文字
世界のさまざまな文字体系を考慮すると、文字の概念は非常に複雑になります。そのため、「文字」をある意味で表すいくつかの異なるUnicode用語があります。コードポイント、グラフェムクラスタ、グリフなどです。
Unicodeでは、コードポイントはテキストの原子単位です。
しかし、グラフェムクラスタは、画面または紙に表示される記号に最も近いものです。「水平方向に分割可能なテキスト単位」として定義されています。そのため、公式のUnicodeドキュメントでは、ユーザーが認識する文字とも呼ばれています。グラフェムクラスタをエンコードするには、1つ以上のコードポイントが必要です。
たとえば、デーバナーガリー文字のkshiは4つのコードポイントでエンコードされています。Array.from()を使用して文字列をコードポイントを含む配列に分割します(詳細は、§20.7.1「コードポイントの操作」を参照してください)。

国旗の絵文字もグラフェムクラスタであり、2つのコードポイントで構成されています。たとえば、日本の国旗などです。
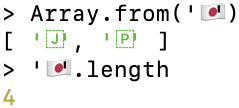
19.3.1 グラフェムクラスタとグリフ
記号は抽象的な概念であり、書かれた言語の一部です。
- コンピュータのメモリでは、グラフェムクラスタ(1つ以上の数値(コードポイント)のシーケンス)によって表されます。
- グリフを介して画面に描画されます。グリフは画像であり、通常はフォントに格納されます。単一の記号を描画するために複数のグリフを使用できます。たとえば、「é」という記号は、「e」のグリフと「´」のグリフを組み合わせることで描画できます。
概念とその表現の区別は微妙であり、Unicodeについて話す際には曖昧になる可能性があります。
![]() グラフェムクラスタの詳細情報
グラフェムクラスタの詳細情報
詳細については、Manish Goregaokarによる“Let’s Stop Ascribing Meaning to Code Points”を参照してください。
![]() クイズ
クイズ
クイズアプリを参照してください。